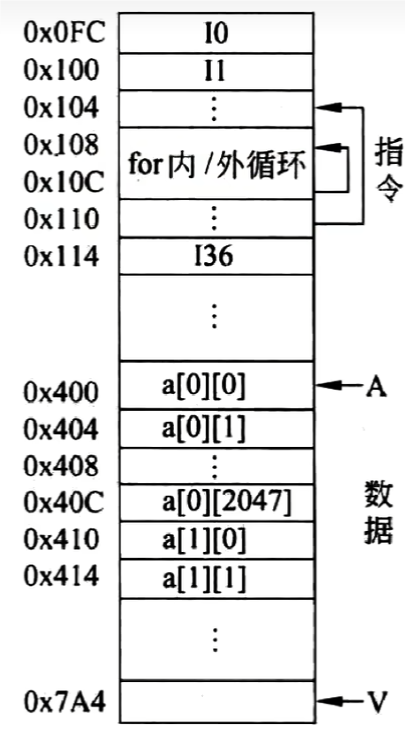
// Cache is a LRU cache. It is not safe for concurrent access. type Cache struct { maxBytes int64 nbytes int64 ll *list.List cache map[string]*list.Element // optional and executed when an entry is purged. OnEvicted func(key string, value Value) }
type entry struct { key string value Value }
// Value use Len to count how many bytes it takes type Value interface { Len() int }
// New is the Constructor of Cache funcNew(maxBytes int64, onEvicted func(string, Value)) *Cache { return &Cache{ maxBytes: maxBytes, ll: list.New(), cache: make(map[string]*list.Element), OnEvicted: onEvicted, } }
// Get look ups a key's value func(c *Cache) Get(key string) (value Value, ok bool) { if ele, ok := c.cache[key]; ok { c.ll.MoveToFront(ele) kv := ele.Value.(*entry) return kv.value, true } return }
// RemoveOldest removes the oldest item func(c *Cache) RemoveOldest() { ele := c.ll.Back() if ele != nil { c.ll.Remove(ele) kv := ele.Value.(*entry) delete(c.cache, kv.key) c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len()) if c.OnEvicted != nil { c.OnEvicted(kv.key, kv.value) } } }
// Add adds a value to the cache. func(c *Cache) Add(key string, value Value) { if ele, ok := c.cache[key]; ok { c.ll.MoveToFront(ele) kv := ele.Value.(*entry) c.nbytes += int64(value.Len()) - int64(kv.value.Len()) kv.value = value } else { ele := c.ll.PushFront(&entry{key, value}) c.cache[key] = ele c.nbytes += int64(len(key)) + int64(value.Len()) } for c.maxBytes != 0 && c.maxBytes < c.nbytes { c.RemoveOldest() } }
// LFU the Least Frequently Used (LFU) page-replacement algorithm type LFU struct { lenint// length capint// capacity minFreq int// The element that operates least frequently in LFU
// key: key of element, value: value of element itemMap map[string]*list.Element
// key: frequency of possible occurrences of all elements in the itemMap // value: elements with the same frequency freqMap map[int]*list.List // 维护一个频率和list的集合 }
// initItem to init item for LFU funcinitItem(k string, v any, f int) item { return item{ key: k, value: v, freq: f, } }
// Get the key in cache by LFU func(c *LFU) Get(key string) any { // if existed, will return value if e, ok := c.itemMap[key]; ok { // the frequency of e +1 and change freqMap c.increaseFreq(e) obj := e.Value.(item) return obj.value }
// if not existed, return nil returnnil }
// increaseFreq increase the frequency if element func(c *LFU) increaseFreq(e *list.Element) { obj := e.Value.(item) // remove from low frequency first oldLost := c.freqMap[obj.freq] oldLost.Remove(e) // change the value of minFreq if c.minFreq == obj.freq && oldLost.Len() == 0 { // if it is the last node of the minimum frequency that is removed c.minFreq++ } // add to high frequency list c.insertMap(obj) }
// Put the key in LFU cache func(c *LFU) Put(key string, value any) { if e, ok := c.itemMap[key]; ok { // if key existed, update the value obj := e.Value.(item) obj.value = value c.increaseFreq(e) } else { // if key not existed obj := initItem(key, value, 1) // if the length of item gets to the top line // remove the least frequently operated element if c.len == c.cap { c.eliminate() c.len-- } // insert in freqMap and itemMap c.insertMap(obj) // change minFreq to 1 because insert the newest one c.minFreq = 1 // length++ c.len++ } }
// insertMap insert item in map func(c *LFU) insertMap(obj item) { // add in freqMap l, ok := c.freqMap[obj.freq] if !ok { l = list.New() c.freqMap[obj.freq] = l } e := l.PushFront(obj) // update or add the value of itemMap key to e c.itemMap[obj.key] = e }
// eliminate clear the least frequently operated element func(c *LFU) eliminate() { l := c.freqMap[c.minFreq] e := l.Back() obj := e.Value.(item) l.Remove(e)